Boostcamp AI Tech (Day 007)
1.강의듣고 퀴즈 오답노트
선형 분류와 Bias Vector
1. 선형 분류(Linear Classification)
- 정의: linear classifier에서 bias vector(b) 값은 데이터 셋이 편향되었을 때 사용되는 상수 항을 의미합니다. 선형 분류는 데이터를 특정 기준으로 나누기 위해 선형 결정 경계(직선 또는 초평면)를 사용하는 분류 방법입니다. 주로 Logistic Regression, Support Vector Machine(SVM) 등이 대표적입니다.
-
모델 수식: 선형 분류 모델
\[y = \mathbf{W} \cdot \mathbf{X} + \mathbf{b}\]여기서 \(\mathbf{W}\)는 가중치 벡터, \(\mathbf{X}\)는 입력 데이터 벡터,\(\mathbf{b}\)는 bias 벡터입니다.
2. Bias Vector
- 역할: Bias는 모델의 출력에 일정한 오프셋을 추가하는 역할을 합니다. 이는 데이터를 특정 방향으로 이동시키며, 모델이 데이터를 더 잘 맞출 수 있도록 돕습니다.
- 오답노트: Bias vector가 데이터와 라벨 사이의 숨겨진 관계를 나타낸다는 설명은 잘못된 것입니다. 실제로, bias는 단순히 결정 경계가 지나가는 위치를 조정하는 역할을 합니다. 숨겨진 관계는 가중치 \(\mathbf{W}\)에 의해 주로 표현됩니다.
Logistic Regression과 Neural Network
1. Logistic Regression
-
정의: Logistic Regression은 이진 분류 문제를 해결하기 위한 통계적 모델입니다. 선형 모델을 사용하여 데이터를 분류하고, sigmoid 함수를 통해 이진 클래스에 대한 확률을 출력합니다.
\[p(y=1|\mathbf{X}) = \sigma(\mathbf{W} \cdot \mathbf{X} + \mathbf{b})\]여기서 \(\sigma(z) = \frac{1}{1 + e^{-z}}\)는 sigmoid 함수입니다.
-
특징: Logistic Regression은 선형 분류기이며, 출력이 0과 1 사이의 확률로 해석됩니다.
2. Logistic Regression과 Neural Network
- 특별한 경우: Logistic Regression은 신경망의 매우 단순한 형태로 볼 수 있습니다. 신경망은 일반적으로 여러 개의 뉴런(가중치와 bias를 포함)과 비선형 활성화 함수를 가진 레이어들로 구성됩니다. Logistic Regression은 단일 뉴런과 sigmoid 활성화 함수를 사용하는 단일 레이어 신경망입니다.
-
구조: Logistic Regression의 구조는 다음과 같습니다:
- 입력층(Input Layer): 특징 벡터 \(\mathbf{X}\)
- 출력층(Output Layer): sigmoid 함수가 적용된 단일 출력 뉴런
RNN 모델에 대한 장단점, 기울기 소실 및 기울기 폭발 문제를 해결하는 방법, 그리고 LSTM과 Seq2Seq 모델
RNN 모델의 장단점
장점:
- 시퀀스 데이터(예: 시계열, 텍스트) 처리에 적합합니다.
- 이전 입력에 대한 문맥을 유지할 수 있습니다.
- 입력과 출력의 길이가 가변적입니다.
단점:
- 긴 시퀀스에 대한 학습이 어려움.
- 기울기 소실(Vanishing Gradient) 및 기울기 폭발(Exploding Gradient) 문제에 취약합니다.
- 순차적으로 처리하므로 학습 속도가 느립니다.
기울기 소실 및 기울기 폭발 문제
- 기울기 소실: 역전파 과정에서 기울기가 매우 작아져 가중치 업데이트가 거의 이루어지지 않는 문제입니다.
- 기울기 폭발: 기울기가 너무 커져 가중치가 매우 큰 값으로 변하면서 모델이 불안정해지는 문제입니다.
해결 방법:
- LSTM: 게이트 구조를 통해 정보를 효과적으로 관리하여 긴 시퀀스의 의존성을 학습할 수 있습니다.
- 기울기 클리핑: 기울기의 크기를 제한하여 기울기 폭발을 방지합니다.
- 배치 정규화: 입력을 정규화하여 기울기 폭발 가능성을 줄입니다.
LSTM과 Seq2Seq 모델
- LSTM: 긴 시퀀스의 장기 의존성을 학습할 수 있는 RNN의 변형입니다. 입력, 출력, 망각 게이트를 통해 정보를 효율적으로 조절합니다.
- Seq2Seq: 주로 기계 번역과 같은 작업에서 사용되는 모델 구조로, 인코더와 디코더로 구성되어 있습니다. 인코더는 입력 시퀀스를 컨텍스트 벡터로 변환하고, 디코더는 이를 바탕으로 출력 시퀀스를 생성합니다.
PyTorch 기반 Seq2Seq 모델 코드
인코더는 입력 시퀀스를 받아 컨텍스트 벡터를 생성하고, 디코더는 이 벡터를 바탕으로 출력 시퀀스를 생성합니다. 학습 과정에서 “Teacher Forcing” 기법을 사용하여 학습 속도를 향상시킬 수 있습니다.
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim, n_layers, dropout):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout=dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, (hidden, cell) = self.rnn(embedded)
return hidden, cell
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim, n_layers, dropout):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout=dropout)
self.fc_out = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
input = input.unsqueeze(0)
embedded = self.dropout(self.embedding(input))
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc_out(output.squeeze(0))
return prediction, hidden, cell
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
hidden, cell = self.encoder(src)
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(trg_len, trg_vocab_size).to(self.device)
input = trg[0, :]
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[t] = output
top1 = output.argmax(1)
input = trg[t] if torch.rand(1).item() < teacher_forcing_ratio else top1
return outputs
2.피어세션 - 깃허브 스터디 2회차
branch & conflict
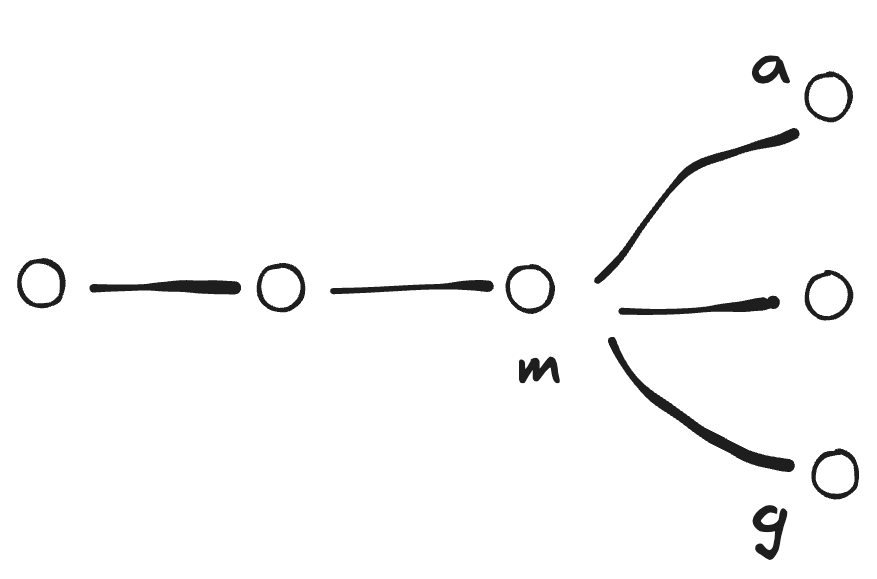 a branch: master branch의 다른 버전(master branch 기반)
master branch: master branch의 업데이트
g branch: master branch로부터의 다른 버전(master branch 기반)
a branch: master branch의 다른 버전(master branch 기반)
master branch: master branch의 업데이트
g branch: master branch로부터의 다른 버전(master branch 기반)
checkout: 새로운 버전 생성 -> master branch 기반의 a branch, g branch에 버전들이 저장됨
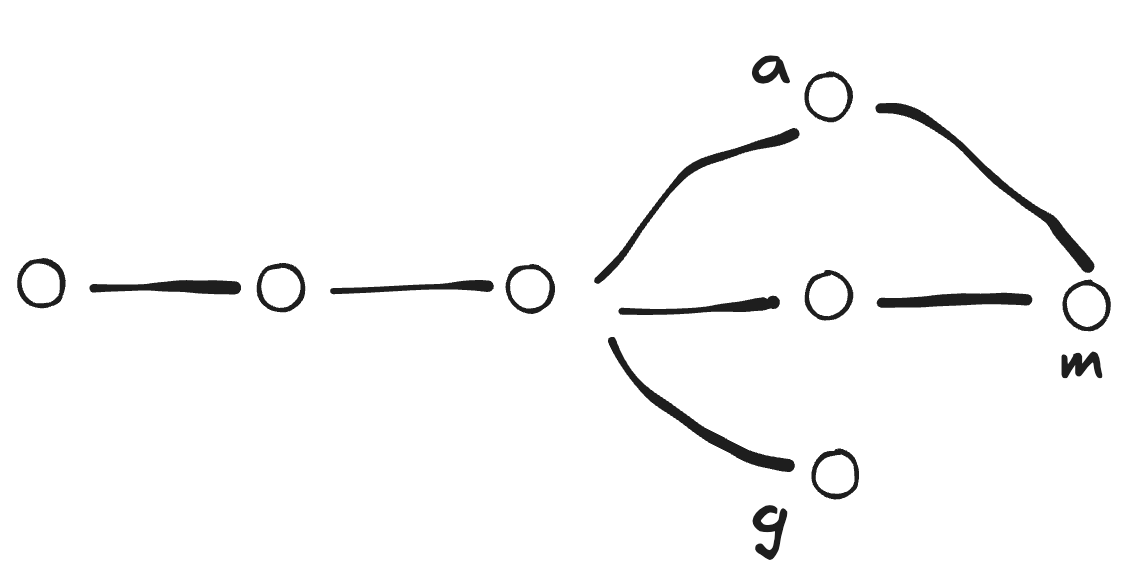 a branch에서의 작업이 master branch에서도 유용할 것 같으면
a branch에서의 작업이 master branch에서도 유용할 것 같으면 merge를 한다.
master branch에서 작업한 내용도 가지고있고 a branch에서의 작업도 동시에 가지고있는 새로운 버전을 생성하고 그 버전은 master branch에도 저장된다.
서로 다른 파일 병합하기
파일 생성 및 커밋
이제 o2 브랜치에서 파일을 생성한다.
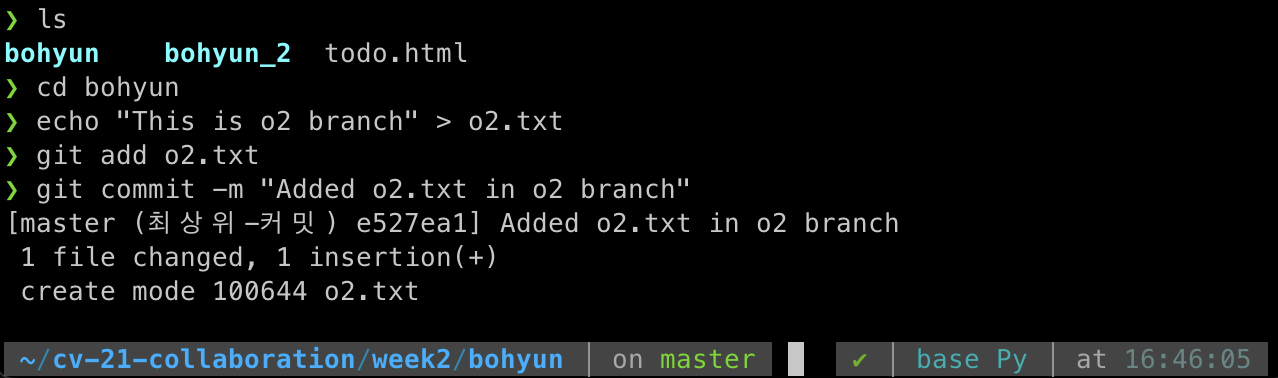 o2.txt라는 파일을 생성하고 커밋하는 과정이다.
o2.txt라는 파일을 생성하고 커밋하는 과정이다.
o2 브랜치 병합
이제 o2 브랜치의 내용을 master 브랜치에 병합한다.
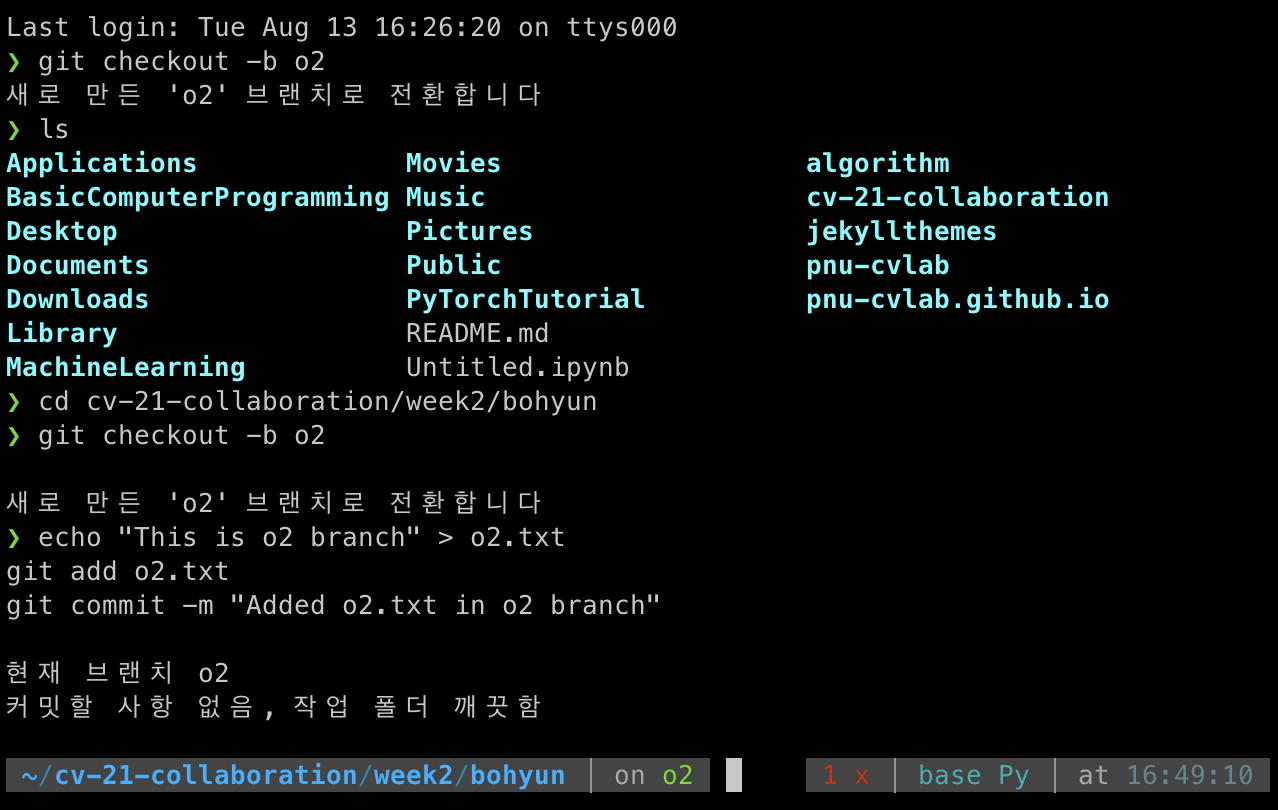
git merge o2
 이 명령어는 병합된 기록을 한 눈에 볼 수 있게 시각화해준다.
이 명령어는 병합된 기록을 한 눈에 볼 수 있게 시각화해준다.
[스터디 내용 요약] Mac에서 Homebrew를 사용하여 Git을 설치한 후, 서로 다른 브랜치(branch)를 병합하는 방법을 설명하겠습니다. 이 과정은 Git의 기본적인 사용법이며, 터미널을 통해 수행됩니다.
1. Homebrew를 사용하여 Git 설치
이미 Git이 설치되어 있다면 이 단계를 건너뛸 수 있습니다. 설치하지 않았다면 다음 명령어를 터미널에 입력
brew install git
2. Git 저장소 초기화
먼저 Git 저장소를 초기화해야 합니다. 프로젝트 디렉토리로 이동한 후, 다음 명령어를 실행
git init
3. 브랜치 생성 및 작업
o2라는 브랜치를 생성하고 이 브랜치에서 작업을 진행하려면 다음 단계를 따릅니다:
(a) o2 브랜치 생성 및 전환
git checkout -b o2
이 명령어는 o2라는 새 브랜치를 생성하고, 그 브랜치로 전환합니다.
(b) 파일 생성 및 커밋
o2 브랜치에서 파일을 생성하고 작업을 합니다. 예를 들어, o2.txt라는 파일을 생성하고 커밋하는 과정
echo "This is o2 branch" > o2.txt
git add o2.txt
git commit -m "Added o2.txt in o2 branch"
4. o2 브랜치 병합
이제 o2 브랜치의 내용을 master 브랜치에 병합합니다.
(a) master 브랜치로 전환
git checkout master
(b) o2 브랜치 병합
git merge o2
이 명령어는 o2 브랜치의 변경 사항을 master 브랜치로 병합합니다. 병합 중 충돌이 발생하지 않으면 병합이 자동으로 완료됩니다.
5. 병합 결과 확인
병합이 완료된 후, 병합된 결과를 확인하기 위해 Git 로그를 확인
git log --oneline --graph
이 명령어는 병합된 기록을 한 눈에 볼 수 있게 시각화해줍니다.
6. 병합 완료 후 o2 브랜치 삭제 (선택 사항)
병합이 완료된 후, o2 브랜치를 더 이상 필요로 하지 않으면 삭제
git branch -d o2
o2 브랜치의 내용이 master 브랜치에 병합되고, 병합된 새 버전이 생성됩니다. 충돌이 발생할 경우, Git이 충돌을 처리할 수 있도록 사용자에게 알리고, 사용자가 직접 충돌을 해결