Boostcamp AI Tech (Day 012)
1. 강의듣기
1.1 데이터 분석 및 시각화
효과적인 강의 수강법
- 목표 설정: AI와 Data Science를 통해 얻고자 하는 목표를 명확히 합니다.
- 논리적 사고: 프로그래밍보다는 논리에 집중해야 합니다.
- 도구 활용: 다양한 도구와 데이터에 대한 이해를 바탕으로 작업을 진행합니다.
- 데이터 이해: AI 모델링만큼 데이터의 전반에 대한 이해가 중요합니다.
데이터 분석 개요
1. 데이터 분석과 결과물
- 고전 통계: 추론(Inference)을 통해 모집단의 특징을 파악.
- 해석: 과거/현재 데이터를 기반으로 현상태를 파악.
- 의사결정: 특정 목적에 맞춰 데이터를 바탕으로 의사결정.
- 예측: 과거 데이터 패턴을 바탕으로 미래를 예측.
2. 데이터 업계의 다양한 장애물
- 명확한 목적의 부재: 데이터로 해결할 수 있는 문제를 정확히 파악해야 함.
- 리소스의 부족: 충분한 리소스가 없는 경우 문제 발생.
- 데이터에 대한 잘못된 인식: 데이터만으로 모든 문제를 해결할 수 있다는 잘못된 인식이 존재함.
데이터 문해력
1. 데이터 문해력 요소
- 질문 역량: 좋은 질문을 통해 데이터의 문제를 파악.
- 데이터 선별: 필요한 데이터를 선별하고 검증.
- 데이터 해석: 데이터를 해석하여 의미 있는 결론을 도출.
- A/B 테스트: 가설 기반 테스트를 통해 결과를 판별.
- 결과 표현: 분석 결과를 쉽게 이해할 수 있도록 표현.
- 데이터 스토리텔링: 의사결정자들이 전체 그림을 이해하고 실행하도록 유도.
2. 좋은 질문과 EDA
- 좋은 질문: 문제 해결을 위한 시작은 좋은 질문에서 출발.
- 탐색적 데이터 분석(EDA): 데이터를 분석하고 해석하는 과정에서 다양한 요소를 고려.
3. 데이터 선별
- 데이터 수집: 올바르게 수집되었는지 확인.
- 예외치 처리: 분석에서 예외적인 데이터를 어떻게 처리할지 결정.
4. 모델과 분석 방법 결정
- 학습 시간: 모델 학습에 필요한 시간을 고려.
- 예측 시간: 예측에 필요한 시간을 고려.
- 비용: 모델 개발 및 운영 비용을 고려.
- 안정성과 보안: 모델의 안정성과 보안을 고려.
5. 결과물 배포와 설득
- EDA: 해석을 위한 적절한 방법론과 효율성을 고려.
- 결과 시각화: 미적 요소를 추가하여 설득력 있는 시각화 도출.
결론
- 기여 영역: 본인이 기여하고 싶은 영역을 명확히 함.
- 습득 영역: 습득하고 싶은 영역을 설정.
- 시각화와 EDA: 각 영역에서 시각화와 EDA의 역할을 고민.
참고 사이트:
2. 심화과제1
잘못된 시각화 모음
잘못된 시각화가 모아져 있는 사이트: viz.wtf
- Visualizations that make no sense. For a discussion of what is wrong with a particular visualization.
시각화의 방법 변경 (방법론, 배치, 색상 등)
- 설명이 부족한 시각화의 경우, 내용 추가.
- 의미 전달을 위해 다른 데이터를 수집할 수 있는 경우, 수집 방법과 데이터 스토리텔링 방법.
- 의미 있게 개선하기 위한 방법을 고민해보자!
추가된 설득에 초점을 둔다.
1. 선택한 잘못된 시각화
링크: 잘못된 시각화 링크

2. 현재 시각화의 문제점 및 개선 방향
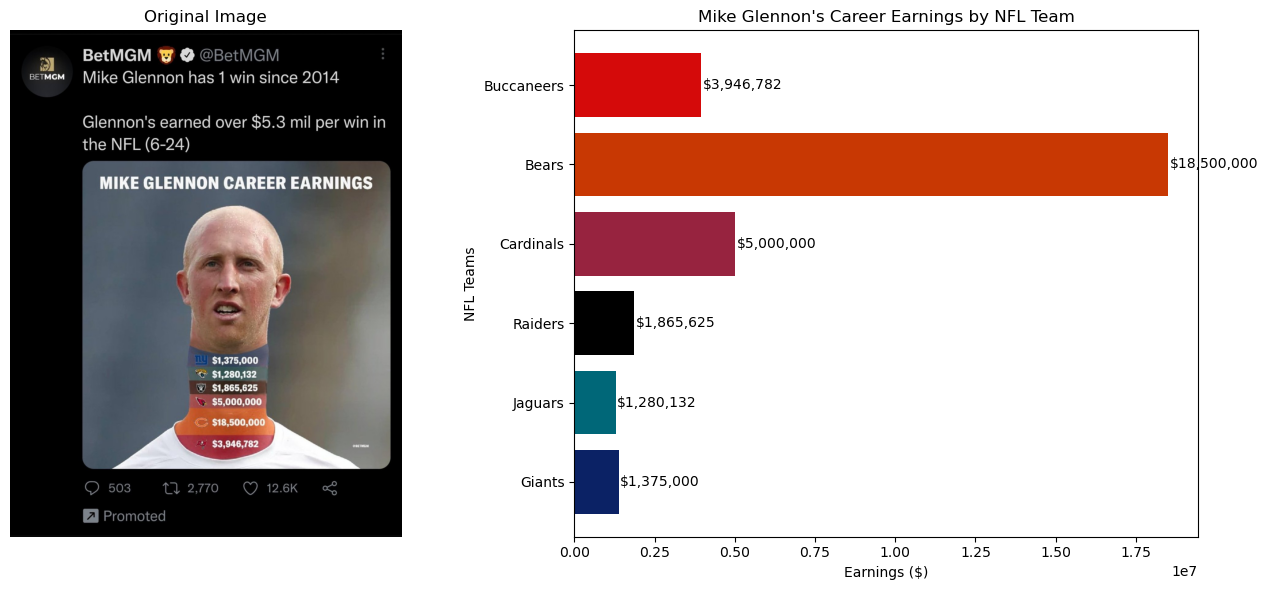 문제점 1:
문제점 1:
목의 길이를 늘려서 수익을 표현하고 단순히 수익을 나열하기 때문에 해석을 위한 시간적 효율성이 떨어진다.
개선 방향 1:
일반적인 막대그래프를 사용하여 각 수익의 차이를 더 명확하게 전달하고자 했다.
문제점 2:
팀을 나타내는 색상과의 연관성이 부족하다.
개선 방향 2:
팀의 공식 색상을 사용하여 각 수익을 시각화했다.
3. 개선된 시각화 제안
설명:
SSH 환경에 Jupyter Notebook을 설치하여 그래프와 이미지를 실시간으로 확인했다.
코드 설명:
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
image_path = '/home/user/Desktop/BOHYUN/naver/week3/image/as_1.jpg'
img = mpimg.imread(image_path)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
ax1.imshow(img)
ax1.axis('off') # 축 숨기기
ax1.set_title("Original Image")
teams = ["Giants", "Jaguars", "Raiders", "Cardinals", "Bears", "Buccaneers"]
earnings = [1375000, 1280132, 1865625, 5000000, 18500000, 3946782]
colors = ["#0b2265", "#006778", "#000000", "#97233F", "#C83803", "#D50A0A"]
ax2.barh(teams, earnings, color=colors)
ax2.set_title("Mike Glennon's Career Earnings by NFL Team")
ax2.set_xlabel("Earnings ($)")
ax2.set_ylabel("NFL Teams")
for i, v in enumerate(earnings):
ax2.text(v + 50000, i, f"${v:,}", color='black', va='center')
plt.tight_layout()
plt.show()
- 이미지 로드 및 표시:
mpimg.imread(image_path)로 지정된 경로에서 이미지를 로드한다.ax1.imshow(img)로 이미지를 첫 번째 플롯(ax1)에 표시한다.ax1.axis('off')로 이미지 주변의 축을 숨겨 이미지만 표시되도록 한다.ax1.set_title("Original Image")로 이미지 위에 제목을 추가하여 이미지를 설명한다.
- 막대그래프 생성:
teams리스트와earnings리스트를 사용하여 각 팀과 그 팀에서 Mike Glennon이 벌어들인 수익을 저장한다.ax2.barh(teams, earnings, color=colors)로 수평 막대그래프를 생성한다. 각 막대의 색상은colors리스트에서 지정한 팀별 색상을 사용한다.ax2.set_title,ax2.set_xlabel,ax2.set_ylabel을 사용하여 그래프에 제목과 축 라벨을 추가하여 데이터를 명확하게 설명한다.ax2.text(v + 50000, i, f"${v:,}", color='black', va='center')로 각 막대 끝에 수익 금액을 표시하여, 수익의 크기를 시각적으로 쉽게 이해할 수 있도록 한다.
- 레이아웃 조정 및 표시:
plt.tight_layout()는 두 개의 플롯이 겹치지 않고 깔끔하게 배치되도록 레이아웃을 조정한다.
3. 심화과제2
풀고 Blog와 Velog에 풀이과정을 업로드했다.
4. 2강 실습
여러 패키지를 이용해서 시각화를 해보았다.