Boostcamp AI Tech (Day 021)

- Cross-modal Reasoning (교차 모달 추론)
첫 번째 이미지에서는 ‘Cross-modal Reasoning’이라는 개념을 다루고 있다. 이는 서로 다른 형태(모달)의 정보, 예를 들어 텍스트와 이미지 같은 정보를 상호 참조하여 의미를 추론하는 과정이다. 세 가지 방법 중 ‘Matching(매칭)’, ‘Translating(번역)’, ‘Referencing(참조)’가 있으며, 그림에서는 ‘Referencing(참조)’ 방법을 강조하고 있다. 이 방법은 서로 다른 모달의 정보를 서로 참조하면서 의미를 도출하는 방식으로, 특히 한 모달에서 얻은 정보를 다른 모달에 적용하여 해석하는 과정이다.
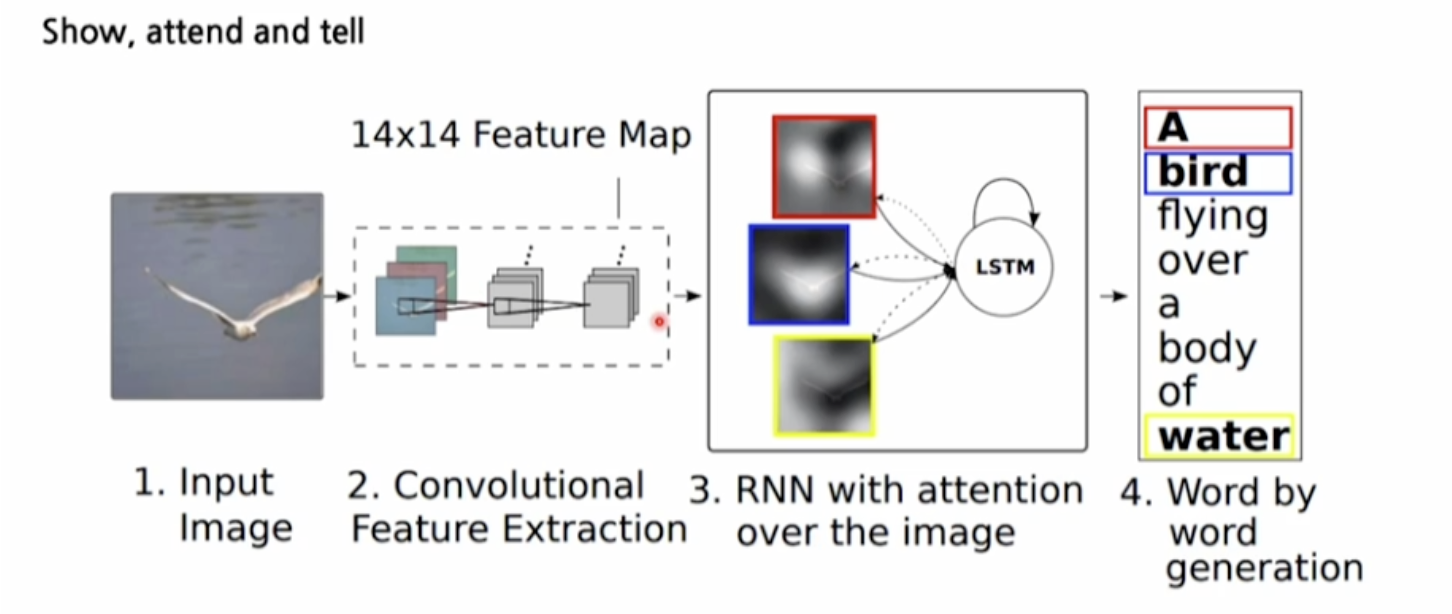
- Show, Attend and Tell
두 번째 이미지와 세 번째 이미지는 ‘Show, Attend, and Tell’이라는 이미지 캡션 생성 방법론을 설명하고 있다.- Input Image (입력 이미지): 이미지가 주어지면, 이를 첫 단계로 입력받는다.
- Convolutional Feature Extraction (합성곱 특징 추출): 합성곱 신경망(CNN)을 사용하여 이미지에서 주요 특징들을 추출한다. 이 과정에서 이미지가 14x14 크기의 특징 맵으로 변환된다.
- RNN with Attention (어텐션 메커니즘을 가진 순환 신경망): RNN(순환 신경망)과 어텐션 메커니즘을 사용하여 이미지의 특정 부분에 주목한다. 즉, 이미지의 여러 부분 중 어디에 주목할지를 결정하는 것이 이 단계에서 이루어진다. 여기서 LSTM(Long Short-Term Memory) 네트워크가 사용되어 순차적인 단어 생성을 돕는다.
- Word Generation (단어 생성): 마지막으로, 주목한 이미지의 정보를 바탕으로 단어를 하나씩 생성하여 최종적으로 이미지 설명 문장을 만들어낸다. 예시에서는 “A bird flying over a body of water”라는 문장이 생성된다.
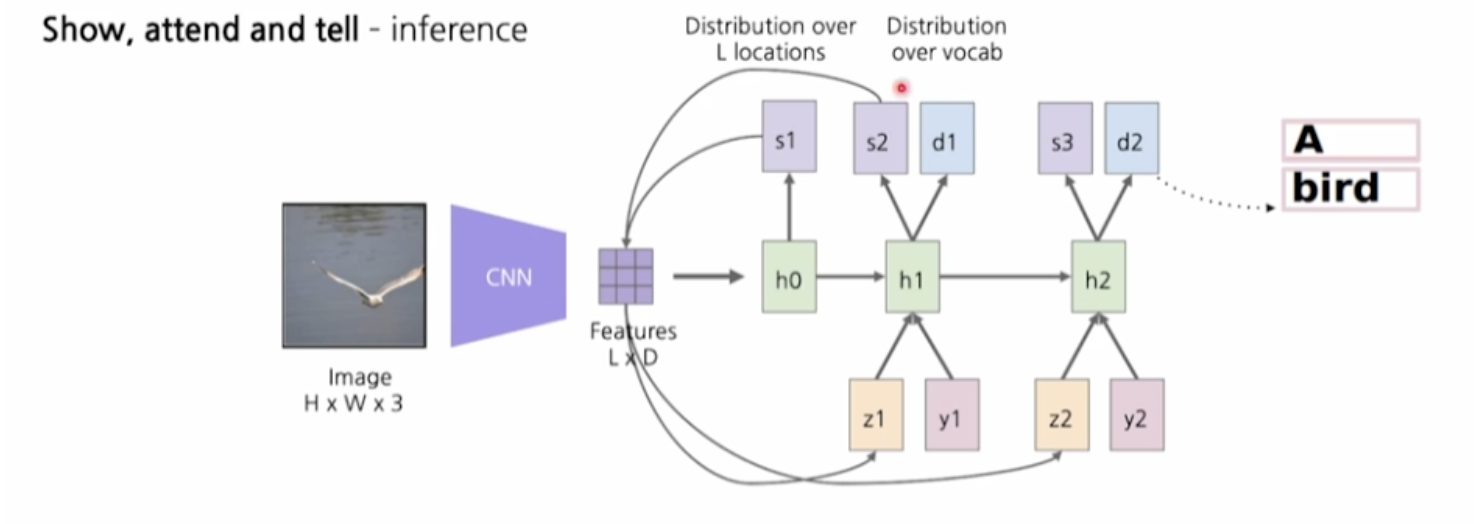 Inference 과정에서는, CNN이 이미지에서 특징을 추출하고, 어텐션 메커니즘을 통해 이미지의 특정 위치에 집중하며 해당 위치의 특징을 기반으로 캡션을 생성하게 된다. 이를 통해 특정 이미지에서 어떤 부분에 주목할지 결정하는 것이 가능해진다.
Inference 과정에서는, CNN이 이미지에서 특징을 추출하고, 어텐션 메커니즘을 통해 이미지의 특정 위치에 집중하며 해당 위치의 특징을 기반으로 캡션을 생성하게 된다. 이를 통해 특정 이미지에서 어떤 부분에 주목할지 결정하는 것이 가능해진다.
-
Few-Shot Learning
Flamingo는 주어진 적은 데이터(few-shot examples)만을 사용해 새로운 정보를 추론할 수 있는 모델이다. 첫 번째 이미지에서는 다양한 입력 프롬프트(input prompt)와 몇 가지 예시를 바탕으로 모델이 출력을 생성하는 과정이 설명되어 있다. 예를 들어, 이미지에서 “이것은 플라밍고입니다”라는 문장을 생성할 수 있다. 이 모델은 학습 예시를 많이 필요로 하지 않고도 높은 성능을 발휘할 수 있는 능력을 가지고 있다. -
Flamingo의 모듈 네트워크
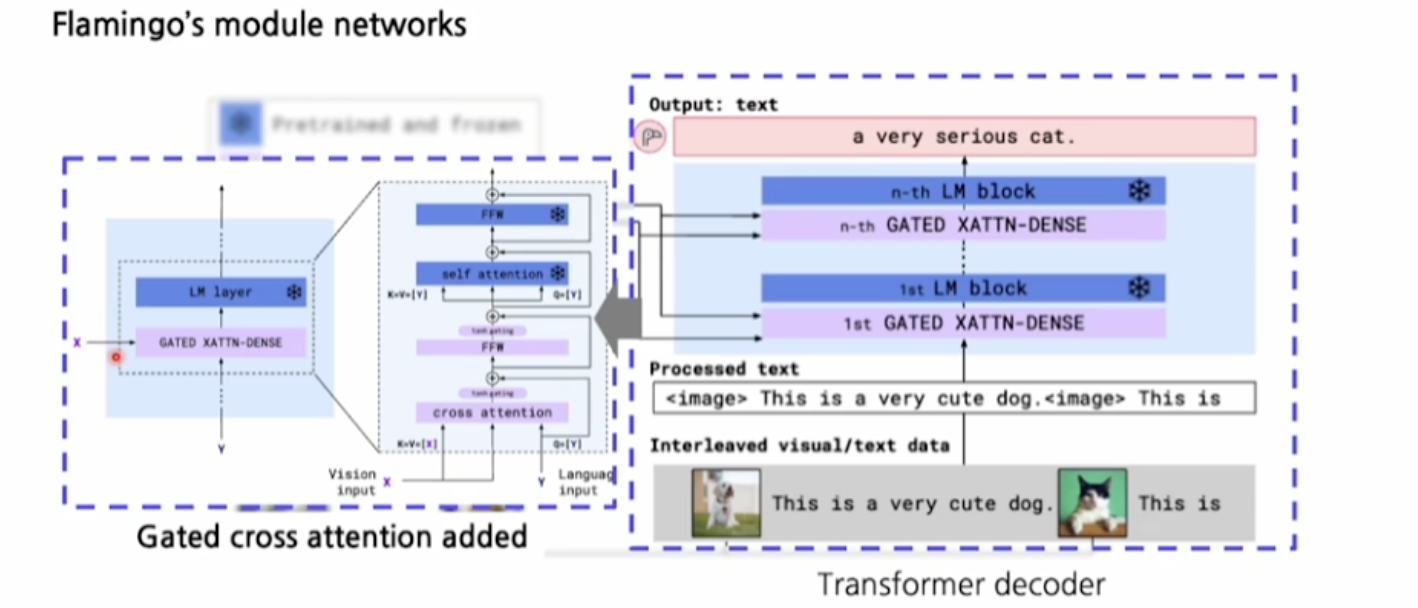
두 번째와 세 번째 이미지는 Flamingo의 네트워크 구조를 보여준다. 모델은 두 가지 중요한 요소로 구성되며, 각각 사전 학습된 비전 인코더와 언어 모델이 있다. 비전 인코더는 이미지를 처리하고, 그 특징을 추출하여 텍스트 생성에 사용된다. 여기서 Perceiver Resampler라는 모듈이 특징을 다시 샘플링하여 텍스트 생성을 돕는 역할을 한다. LM 블록(Language Model Block)은 이미지와 텍스트 간의 관계를 모델링하며, 교차 어텐션(cross attention)을 통해 이미지와 텍스트 간의 상호작용을 학습한다. - Gated Cross Attention과 Transformer Decoder
마지막 이미지에서는 Gated Cross Attention 메커니즘을 사용하는 Transformer 디코더 구조가 설명되어 있다. 이 구조는 언어와 이미지 간의 상호작용을 강화하기 위해 tanh 게이팅을 추가하여 어텐션을 조절한다. 이를 통해 이미지를 보다 정밀하게 분석하고 텍스트로 변환할 수 있다.

-
테디베어 이미지 예시
첫 번째 대화에서는 달 위에 있는 두 마리의 테디베어 사진에 대해 대화가 진행된다. 질문자는 “그들이 무엇을 하고 있는가?”, “그들이 사용하는 물건은 무엇인가?”와 같은 질문을 통해 이미지를 분석하고, 모델은 “그들이 대화를 하고 있다”, “그것은 컴퓨터처럼 보인다” 등의 답변을 제공한다. 이 대화는 단순한 이미지 분석을 넘어서, 이미지 속 맥락을 이해하고 논리적인 추론을 한다. -
플라밍고 이미지 예시
두 번째 대화는 세 가지 플라밍고 이미지에 관한 것이다. 첫 번째 플라밍고는 만화 캐릭터, 두 번째는 실제 플라밍고, 세 번째는 3D 모델이다. 질문자는 이 이미지들 사이의 공통점과 차이점을 묻고, 모델은 이에 대한 답변을 하며 차별화된 정보들을 제공한다. -
아이팟 스티커가 붙은 사과 이미지 예시
세 번째 대화에서는 사과에 ‘아이팟(iPod)’ 스티커가 붙은 사진에 대해 설명이 이루어진다. 스티커의 내용, 글씨체, 사진이 찍힌 장소 등을 묻고 답하는 과정을 통해 이미지에 대한 세부적인 분석을 수행한다. -
도시 풍경 이미지 예시
마지막 대화는 시카고와 도쿄의 도시 풍경에 대한 것이다. 시카고의 건축물(셰드 수족관)이나 도쿄 타워 같은 랜드마크를 인식하여, 모델이 어느 도시인지 추론하는 과정을 보여준다.
-
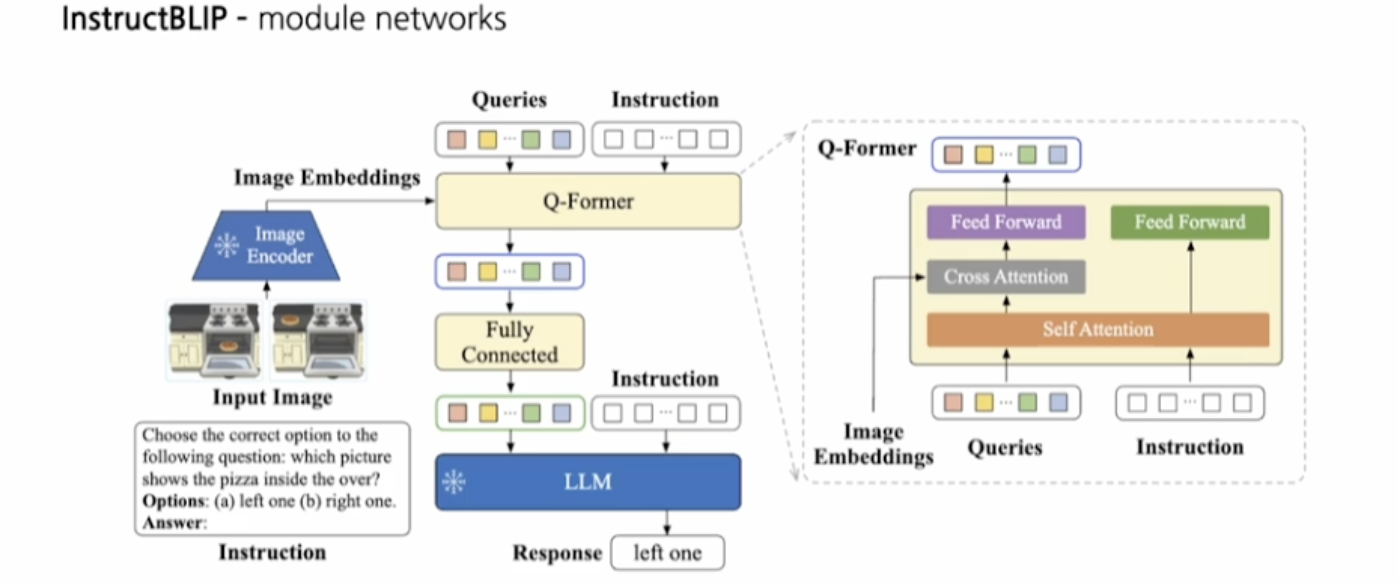
입력 이미지와 질문
모델은 먼저 두 개의 오븐 사진을 입력받는다. 그 후 주어진 질문에 따라, “어느 사진에 피자가 오븐 안에 있는가?”라는 질문과 함께 두 개의 선택지(a: 왼쪽, b: 오른쪽)가 주어진다. -
이미지 임베딩
입력된 이미지는 Image Encoder(이미지 인코더)를 통해 임베딩(벡터로 변환된 이미지 특징)으로 변환된다. 이 임베딩은 Q-Former라는 모듈로 전달된다. -
Q-Former와 크로스 어텐션
Q-Former는 이미지 임베딩과 쿼리(질문)를 결합하여 이미지와 관련된 정보를 추출한다. 이 과정에서 크로스 어텐션(cross attention) 메커니즘이 사용되며, 이 메커니즘은 이미지와 텍스트(질문) 간의 상호작용을 통해 중요한 특징을 강조한다. -
LLM(Long Language Model)와 응답 생성
이미지 임베딩과 질문이 LLM으로 전달되며, LLM은 입력된 정보를 바탕으로 “left one(왼쪽)”이라는 응답을 생성한다.
-
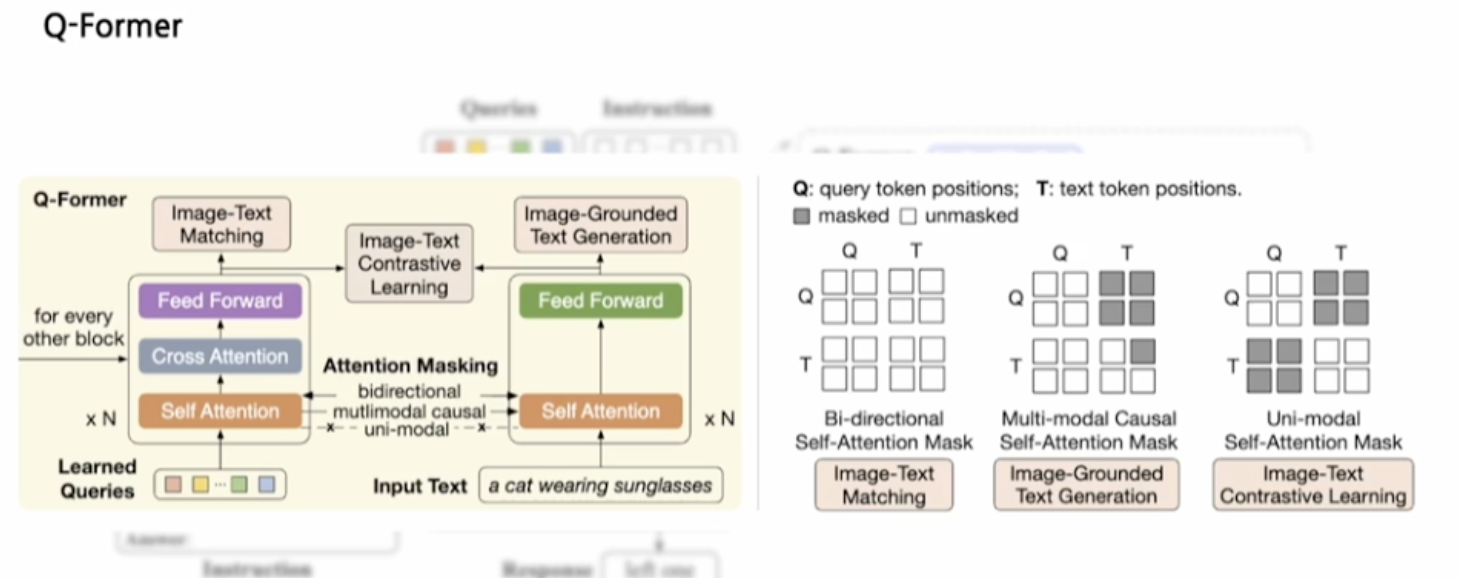
Q-Former의 역할
Q-Former는 이미지와 텍스트의 상호작용을 다루는 모듈로, Image-Text Matching(이미지-텍스트 매칭)과 Image-Grounded Text Generation(이미지 기반 텍스트 생성)을 수행한다. 즉, 주어진 이미지와 텍스트를 비교하거나, 이미지를 바탕으로 텍스트를 생성할 수 있다. -
크로스 어텐션과 셀프 어텐션
Q-Former의 주요 구성 요소는 Cross Attention(크로스 어텐션)과 Self Attention(셀프 어텐션)이다. 크로스 어텐션은 이미지와 텍스트 간의 상호작용을 학습하며, 셀프 어텐션은 이미지와 텍스트 각각의 특징을 학습한다. 이러한 어텐션 메커니즘을 통해 이미지와 텍스트 사이의 연관성을 파악할 수 있다. -
Attention Masking
어텐션 마스킹(Attention Masking)은 양방향(bi-directional), 다중모달(multimodal), 단일모달(uni-modal) 어텐션을 제어하는 방법으로 사용된다. 이는 모델이 어떤 정보에 집중해야 하는지를 결정하는 데 도움을 준다. 예를 들어, 이미지를 기반으로 텍스트를 생성할 때는 다중모달 마스크를 사용하고, 이미지와 텍스트를 비교할 때는 양방향 마스크를 적용한다. -
학습된 쿼리와 입력 텍스트
모델은 학습된 쿼리(queries)를 통해 입력 텍스트와의 관계를 분석하며, 예시로는 “a cat wearing sunglasses”와 같은 입력 텍스트를 처리한다. 이 과정에서 쿼리와 텍스트의 관계를 학습하며, 최종적으로 이미지와 텍스트를 결합한 출력을 생성한다.